 区块链神吐槽
区块链神吐槽最近,随着区块链技术在各大媒体上大肆报道,人们对区块链的态度分为两级。
一种看法是百分百的拥护和信奉,将“去中心化”时时刻刻挂在嘴边,好像只要去了中心化,整个地球就和平了,人类就超脱升华了。
另一种看法则来自“古典”的技术派,认为区块链就是炒作,“去中心化”没有任何实际应用价值,仅仅是用来投机的一种方式,完全嗤之以鼻。
在从事多年数据库工作的巨杉数据库CTO王涛看来,这两种看法都是不负责任的。
在他看来,目前业界的程序员基本对区块链的理解还停留在“小伙子在广场对姑娘说我爱你,让所有人记录下来”的层面。
这种说法作为讲给大妈听的故事不错,但是从技术人员的角度来看,这实际上是一种非常不靠谱的理解,将区块链中的一些精髓设计给掩盖起来了。
- 传统IT从业者到底应该如何从本质来理解区块链的技术原理呢?
- 区块链与数据库到底是什么关系?
- 区块链在当前到底有什么实实在在的技术应用场景?
带着这些问题,区块链大本营特别采访到巨杉数据库CTO王涛,希望他能详细解答我们的疑问。
从传统IT的角度到底应该如何区块链的技术原理?
从宏观看,区块链和分布式数据库的原理、机制这些几乎是一致的。
区块链这一技术的原理其实并不非常复杂,而且与数据库技术的很多原理是一脉相承的。
那么从最本质的功能来看,不管是数据库还是区块链,都是用来存数据的技术。因此,区块链的概念可能引申出了很多商业方面的革新,但是抛开这些上层建筑,从底层地基来看,区块链可以认为是一种特殊的数据库技术。
对于传统数据库来说,经历了网状数据库、层次型数据库以后,从上世纪八十年代以来,关系型数据库一直处于业界统治地位,在所有数据存储体系里是食物链最上层的“霸王龙”。所有学计算机的同学们在大学里学到的就是关系型数据库,在工作里用到的MySQL、Oracle也是关系型数据库,因此可能会产生“数据库就是SQL和表结构”这样的误解。
实际上,数据库只是一种用来存储和查询数据的工具,仅此而已。
SQL是一种大家用的比较多的手段,而当前除了SQL业界还有NoSQL、NewSQL等一大堆变形。因此,大家先把思路放宽,将“数据库”的概念扩展到一切可以保存与获取数据的机制。
那么来看区块链技术,不管是比特币还是以太坊,或者其他变体,其核心本质都是面向交易业务的数据存储于读取能力。
现在大家把它看做是一个拥有很多分拷贝的潘多拉魔盒,只要往里写了东西就可以很快速地在其他拷贝中显现出来。从数据库的角度来看,这就是所有数据库从业人员几十年来一直追求的异地多活机制。
因此,区块链技术即异地多活数据库技术,是各位程序员同学理解区块链本质的核心思想。
区块链技术和传统数据库在机制中的相同点
如果大家了解数据库内核结构,可以看到区块链的核心架构是数据库核心架构一个子集。
区块链的“账本”就相当于数据库的“日志”,数据库是将操作按照顺序写入日志,在区块链里面叫做账本。
区块链技术的设计和机制,与传统数据库的内核理念极为相似。
譬如,从其传输和存储的数据结构上来看,区块链的链式结构来源于传统数据库的事务日志。任何数据库的DBA都知道,数据库的事务日志本质上就是不可更改的链式结构,事务中的每一条操作记录都会有一个反向指针指向该事务中的上一条记录。因此,区块链的链式结构本质上脱胎于数据库事务日志,同时增加了区块之间的反向哈希值作为指针,且引入了默克尔树结构进行快速数据校验。
因而,我们可以安全地进行认为:区块链的链式结构在存储体系中等价于数据库的事务日志。本质上数据库的任何操作同样是不可篡改的,只不过当前大部分数据库不会对外暴露事务日志的解析工具,仅保存每一条记录的最终状态而已。
此外,区块链的共识部分也脱胎自数据库的一致性管理机制。比如传统数据库的主从结构(例如IBM DB2的HADR、Oracle的DataGuard)就是在多个节点之间实时复制数据的一种方式。
当然,和区块链比起来这种方式一方面是做不到传说中的“去中心化”,另一方面只能有一个节点作为主节点负责读写,其他节点作为从节点只读,而无法完全做到异地多主多活的拓扑结构。
而分布式数据库(如NoSQL)使用了多副本自动选举的机制,业界大家都在谈论的Paxos、Raft就是典型的多副本一致性管理算法,与区块链中PBFT等机制存在异曲同工之处。
所以区块链更像是一类拥有特定架构并为特定目的而设计的分布式数据库。
区块链技术在和传统数据库两者机制中的不同点
区块链与传统数据库的本质相同,而所有的不同点都来自于“去中心化”,也就是“异地多活”这个前提。
就好像新型分布式数据库与传统数据库相比,所有的设计变更都来自于“PC服务器内置盘替代外接盘阵”这个前提。区块链技术中不论是UTXO、nonce、PoW、PoS、数字签名等一系列听起来很“高大上”的东西,其目的都是围绕着解决“异地多活”这个困扰着数据库行业专家20多年的硬骨头来设计的。
我们先简单从事务与一致性算法这两个方面,来看看区块链与数据库技术的核心差异在哪里。
从事务功能来看,数据库的事务机制就是为了保障通用场景下的一致性原子操作。而区块链技术为了满足异地多活的前提,将原子操作通过特殊的事务日志结构,抛弃了通用业务场景,而是百分百集中到支付与结算业务,从而实现了结算场景下的异地多活原子操作。
举个例子,比特币使用的UTXO结构在跨远距离网段的多活架构中,是一种替代传统事务交易日志结构的方式,将几个操作合并在一条事务记录里面作为原子操作发送,而不是每条记录的更改都作为独立的记录,并通过反向指针串联起来。同时,UTXO并不存储每条记录的最终结果,而是存储变更过程,这与传统数据库中事务日志的存储机制有着理念上的区别,之后我们会详细讨论为什么在区块链模型中使用UTXO的价值所在与局限性,以及如果采用传统日志方式所引发的局限性和可能的解决方案。
实际上,和传统事务机制比起来UTXO的理念并不复杂,同时目前UTXO对于通用事务来说局限性很大,无法用于非支付类业务的场景,但是这种思路未来也许会成为多活数据库中支持通用事务的一种基础,值得所有数据库领域的从业人员深入思考。
当然,当前的UTXO结构的执行效率优化也是很大的问题。
像在比特币当前的代码实现中,CTxMemPool对象中存在大量的持有全局锁函数。由于UTXO需要追踪每一个coin的花费流程,在内存中形成一个巨大的树状模型,因此绝大部分需要跟踪交易的操作都需要对内存池进行全局锁定,导致执行效率相对低下。相比起传统数据库缓冲池的数据页模型,比特币的UTXO实现方式有待进行大量优化和提升。
而共识部分则对应着传统的一致性算法,也就是解决“谁应该写”的问题。
现在用的什么PoW、PoS、DPoS、PBFT之类的算法,其实就对应了数据库的一致性算法,本质上就是决定谁来作为永久化日志存储的基准。在多活架构中既然每个节点都能进行写入操作,为了让大家达成一致必须在某个时刻向一个节点看齐。这个时间跨度是像比特币那样每十分钟,还是像以太坊那样每十几秒,还有用什么方式决定谁是这个基准节点,就是所谓共识算法的核心。
对于“谁应该写”的衍生问题,就是“写的东西是不是真实”。这个问题在传统数据库体系是默认排除的。
区块链的共识算法另一个需要解决的问题就是拜占庭问题。如今,链在公网上,并不知道其他对等节点是不是靠谱的,这才是共识算法难以得到突破的关键。既要满足功能层面的需求,还要从算法上保证不靠谱的个别节点不会影响整个网络的一致性共识。
其他的数字签名之类的都是小特性,基本搞IT的兄弟都很明白,在这里就不多说了。
区块链数据库技术
现在“古典”和“区块链”的概念大家吵的很火热,在技术领域也不例外。
经过一段时间的深入了解,我看到作为第一批区块链技术的实现,传统比特币与以太坊在共识机制、存储机制、智能合约机制、跨链通讯机制等领域并没有非常严密的设计。
这些技术的不严密,就引发了一些在数据库与存储领域比较常见的问题,导致其数据规模无法无限增加,比如当前ETH几百GB就产生了严重的性能瓶颈,几乎不可能到达上百TB规模,吞吐量极为有限,这样单位吞吐量基本上没办法适应通用分布式数据存储或通用结算体系的要求。
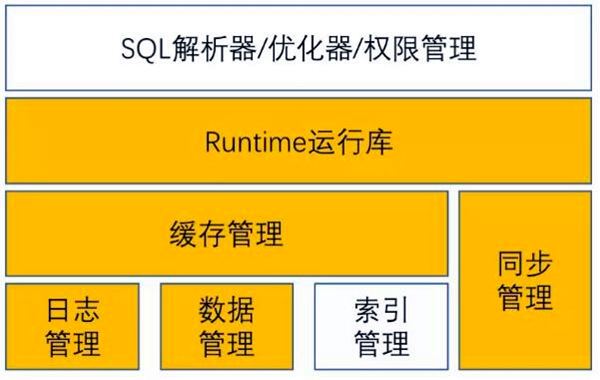
从产品功能的角度看,当前的区块链产品与数据库相比存在极大的差距。尤其是对于在业界存在了几十年的关系型数据库,其主要核心功能包括增删改查,而主要结构则包括SQL解析、日志、数据管理、以及索引管理几大模块。因此从功能上看,当前区块链可以说是一个极简的多活数据库模型,功能支持仅仅是数据库的一个微小子集。
现在的区块链技术还处于0.1版本的时代,就好像80年代各个数据库技术百家争鸣的年代一样,各自都在提出新的架构和观点。
因此,当我们使用变化的眼光来看待区块链的时候,很多当前的问题实际上并不是不可解决的。例如每秒钟3笔交易的比特币技术,是不是意味着UTXO模型不行呢?当然不是。
我们只有当正确理解每一个设计的核心思想以及其局限性,才能用动态发展的眼光看待新技术,了解掩藏在不同产品特性后面的深层次本质与原理。
所以我认为,区块链技术的未来发展,主题是“融合”。就好像之前NoSQL与NewSQL之争,最终也都演进到两者融合成为Multi-Model Database一样,在区块链与传统数据库技术越来越多互相融合后,最终会形成一个更有效的数据管理体系。
分布式数据库和区块链技术的融合
分布式数据库和区块链技术的融合,我认为两者结合点非常非常多。
区块链弥补了原有数据库机制的多活之间事务的难点,其创新在于支持多活架构。全世界无数传统数据库专家,从上世纪90年代就开始研究分布式多活数据库,但是到现在也没有任何成型的理论和实现,在最近二十年一直无法突破的领域。
在区块链技术上,它抛开了强一致和通用事务能力,在对交易和结算领域使用特定的数据结构与算法实现了这种机制,实际上是一种非常跨时代的思路,绝对值得所有数据库行业的从业者借鉴和反思。
而分布式数据库就将发挥其特性,包括数据的扩展性、高并发、高性能以及快速的标准化访问还有更灵活的使用场景。
通过两者技术结合,将会形成数据库为基础的去中心化管理机制。通过分布式数据库,提供了通用的事务支持,高并发、高性能以及所有包括增删改查、SQL解析、日志、数据管理、索引管理等主要功能。而对区块链技术的融合,
将解决多活数据库的“双花问题”也就是一致性控制的问题,还能解决公网内的信任问题以及整个数据的更高安全性。
如果想用现实的场景来举例,就不得不将区块链和业务模式捆绑到一起。其实可以这样简单来看,凡是需要使用到异地多活机制的存储,原则上都可以使用区块链技术来完成。当然,这么说有点粗暴,里面还涉及到一大堆例如强一致性、吞吐量之类的需求,但是为了简单起见大家可以先这么理解。
举例来说,如果把淘宝看做是中心化设计的一个巅峰,全球最大的百货商店,所有开网店的店主都要求着阿里爸爸给自己首页推荐,那么去中心化的淘宝可以认为是,只要想要开网店的小姑娘,通过下载一个“区块链淘宝”的系统,就可以免费自由地向这个本地数据库写入自己要开网店的信息,并把需要卖的东西挂到商店里。然后这个系统通过区块链技术与网上其他所有店长的系统相连,这样小姑娘就可以不需要花任何“租金”就能开网店啦。同时每一笔交易也“没有中间商赚差价”,从而完全免除了“店大欺客”所带来的危害。
巨杉数据库对于区块链技术方向规划?
正如上文所说的模式,巨杉数据库通过分布式拓展性、高性能高并发以及SQL支持等重要特性,目前已经成功的在一些区块链的应用中得到使用。同时通过我们自身技术团队在数据库、分布式架构等等领域的丰富经验,巨杉也在区块链算法上进行了创新,并且将两者进行了有机的结合,可以说正在逐渐实现我们所提到的两种技术融合的过程。
此外,巨杉数据库基于在企业级市场的丰富经验,还将会通过技术融合,让更多的用户更好的应用区块链技术。
我们巨杉接下来一段时间的产品线设计已经受到了区块链技术的很多启发,未来大家可能会看到数据库与区块链技术更加完美的结合。
如果传统IT人想入门或者融合区块链的技术理念,您有什么好的建议呢?
搭建测试环境,看代码,gdb跟踪,真正沉下心死磕某一个区块链底链,把里面的机制理解透彻。作为入门教材,大家可以看看比特币的代码。比如将bitcoind编译完了搭建个测试网络,从头一步步跟踪代码流程,是深入理解PoW、UTXO等机制最有效的方式。
而且我认为,最好的了解办法就是阅读这几个算法、机制相关的论文资料。因为这些才是设计者真实设计理念、原理的严谨记录,所谓的“解读”和“翻译”很可能会忽略了一些部分或者曲解了一些最初的意思。
另外,从我本人的经验来看,阅读开源项目的开发者指南和代码,是最好的理解产品设计思想的方式。
SequoiaDB巨杉数据库的联合创始人&CTO
王涛曾是北美IBM DB2 Lab核心研发成员,有着超过十年的数据库核心架构设计,数据库引擎研发和企业级数据库应用的经验。王涛同时对区块链技术,分布式架构,分布式算法,区块链以及去中心化业务应用有着深入的了解。
2012年公司成立以来,王涛先生一直主导着SequoiaDB产品的架构设计与开发,并在业界对未来数据库、大数据、区块链技术发展进行全力地推动。
王涛作为SequoiaDB巨杉数据库的两位创始人之一,目前担任SequoiaDB的CTO与总架构师。在王涛先生的领导下,SequoiaDB的技术团队从零开始打造的分布式数据库,如今SequoiaDB目前已经拥有超过30家大型银行用户,以及近百家企业用户,并已经在多个银行核心系统投入生产,并于2017年入选国际技术分析机构Gartner的数据库年度报告。


